


2019.12.04
FA回答集(自由回答集)とは
FA回答集(自由回答集)とは・・・ 自由回答(FA)の設問を1問ずつ抜き出した一覧のことを言います。 自由回答に属性(性別、年齢)などの情報……



公開日:2020.03.04
テキストマイニングとは、大量の記述された文章(テキストデータ)を単語や文節に分割し、その出現頻度や相関関係などを分析する技術のことで、最も代表的なデータマイニングのひとつです。文章(テキストデータ)の、可視化及び定量化に有効で、コーディングだけではみえないポジティブ・ネガティブの要素や、単語の繋がりを見ることができます。
数値などの形であらわされる定量データに対し、口コミや検索キーワード、コールセンターでの発言録やwebサイトでの問合せ文など、単語の羅列や文章として表されるテキストデータは定性データと呼ばれ、数値で測れない感情的な側面を持ちます。
昨今はSNSの普及や音声認識機能による音声データのテキスト化など、定性データの分析が必要な局面が急激に増えています。定性データは性質上、リアルタイムで市場の状況・環境、消費者のマインド等を反映しているため、これらをいち早くキャッチし、マーケティングに活かしていくことが今後のビジネスにおいても非常に重要となります。テキストマイニングにより、単語が持つ意味や繋がりを可視化することができるため、感情分析やペルソナ構築のひとつとしても用いられ、マーケティングやブランディングの方向性の舵取りにも大いに役立てることができます。
こちらは当社で実施した自主調査「自分へのご褒美に関するアンケート調査」内で聴取した、「あなたにとっての“自分への理想のご褒美”とはどのような事ですか。」という質問に対する1,000名分の自由記述式回答をテキストマイニングにより単語の出現頻度と相関関係を可視化したものです。
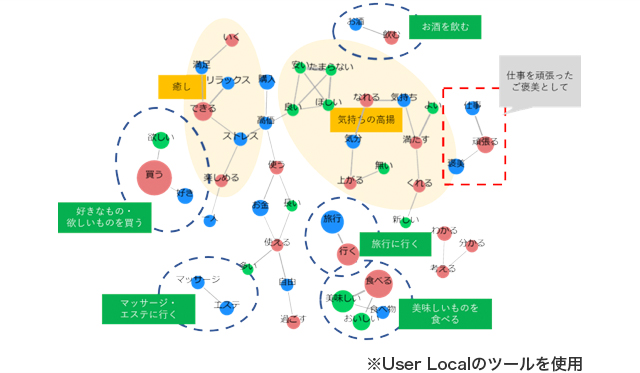
仕事を頑張ったご褒美として、“美味しいものを食べる”“お酒を飲む”“好きなもの・欲しいものを買う”“旅行に行く”“マッサージ・エステに行く”などの行動をして、“気持ちの高揚”や“癒し”を得ることが自分への理想的なご褒美だと答えていることがわかります。
バブルの色は品詞(動詞・名詞・形容詞など)により分けられており、出現頻度が多い単語ほどバブルが大きく、共起の程度が強いほど線が太くなっています。男女別、年代別、役職別などでグラフは変わりますので、傾向を比較してみても良いでしょう。
一般的にはテキストマイニングの専用ツールを使います。専用ツールのボタンひとつで、テキストデータを単語レベルに分解し、品詞ごとにジャンル分けし、重要度を(TF-IDF法という統計処理をかけて)重みづけした上、単語のスコアリングをすることができます。また、単語の出現頻度と同時に現れる共起語も算出できるため、共起語の出現頻度により単語間の結びつけまで自動で行なうことができます。出現傾向が似た単語は“まとまり”としてクラスタリングされます。
専用ツールを使わない場合は、上記全てを手作業で行なう必要があります。工数が多くかかるだけでなく、TF-IDF法などの高度な知識も必要となるため作業としての難易度は高くなるでしょう。
マーケティングリサーチの場合、前述のようなアンケート調査の自由記述式回答の分析手段として最も多く用いられます。アンケート調査の場合、成果物は定量データであるため集計や分析がしやすいのですが、自由記述式回答だけはテキストマイニングをしなければ分析ができません。特に、調査慣れしていない方が作った調査票は、自由記述式回答が多い傾向があり、設問間の相関がなされていない設計になっていることが多く、定量的に正しく分析をかけるのが難しい場合があります。データを可視化して捉えることができなければ、せっかく調査を行なったにも関わらず、誤った経営判断をしてしまう可能性が高くなります。テキストマイニングを用いることで、自由記述式回答が多い調査でも結果を可視化し、正しく結果データを見ることができるので、調査慣れしていない方でも活用しやすい分析方法だといえるでしょう。
他に、定性調査であるインタビュー調査や日記調査、エスノグラフィ調査などで取ったテキストデータもテキストマイニングを行なうことがあります。テキストマイニングのアウトプット単体では、調査全体のアウトプットとはなり得ないため、あくまで部分的なアウトプットとして、感情分析やペルソナの構成要素へ活用されます。
ビッグデータ時代に突入し、テキストマイニングが必要になるケースが非常に増えています。定性データの分析を頻繁に行なう立場にある方は、テキストマイニングを積極的に活用してみてください。マーケティングリサーチにおいてテキストマイニングが必要な場合は、当社にて実施ができますので、是非ご相談ください。
2019.12.04
FA回答集(自由回答集)とは・・・ 自由回答(FA)の設問を1問ずつ抜き出した一覧のことを言います。 自由回答に属性(性別、年齢)などの情報……
2019.12.05
判別分析とは・・・ 目的 数量化Ⅰ類とは逆で、量的変数から質的変数を予測 例 体重・血圧、肝臓の検査結果から、脳卒中になるorならない(……
2019.12.05
ペアコン(Paired Comparison Test)とは・・・ 一対比較テストのことです。2製品比較評価法とも言います。対象者は2製品をテスト使用……
2019.12.05
設問間クロスとは・・・ 設問間クロスとは、質問間の因果関係を調べる方法です。単体の設問では、結果が読み取りにくい設問でも、設問間でクロス集計をかけ……